

Model-based Book Recommendation Engine
With the increase in the number of books and ways to read books, it has become difficult for readers to choose a book to read. In this digital era, we can recommend a book to the reader based on various factors such as his interests, reading habits, and reactions to other books. There are a few recommendation systems available that will use either the characteristics of books or users. In this project, we are proposing a novel approach to recommend books based on the characteristics of both books and users using a matrix factorization method.
Data Description
Data Source: Zajac, Z. (2017).Goodbooks-10k: a new dataset for book recommendations Fast ML
Modeling
The algorithm tries to match and recommend items that are like those which are rated highly by the user. The characteristics of the items are to be known to perform Content-based Filtering. In this case, the tags assigned to books and the authors of the books are considered. A text corpus of this information is created for each book in the dataset. The TF-IDF (Term Frequency- Inverse Document Frequency) approach is used to weight the tags based on their frequency in the corpus. It is also known as Vector Space Representation. Cosine similarity is calculated between books based on the created vector. The calculated cosine similarity is used to recommend a book based on a previously highly rated book. The book that has the highest cosine similarity value with the previously liked book will be recommended to the user. In this approach, more than one previously rated book is considered, and more than one recommendation is made based on their cosine similarity values.

In Collaborative Filtering, the similarity between users is used to recommend books to a user. The previous history of ratings of all the users is collected. The nearest neighbor user-based approach is used in building the recommendation system. The similarity measures Mean Squared Difference (MSD) and Pearson correlation coefficient are compared for the algorithm. The MSD appeared to give a better value of RMSE with KNNWithMeans algorithm in the surprise package. The ratings of k or a smaller number of neighbors are aggregated by considering the mean of ratings given by the user. The ratings a user would give to each book are predicted based on the ratings given by similar users.

Matrix Factorization is a class of Collaborative Filtering used in the Recommendation System. When the features of the user or items are unknown, it becomes difficult to build a recommendation model. In such cases, the most common practice is to generate embeddings, which is another name for latent factors, and let the model determine the weights of these embedding using Singular Value Decomposition (SVD). Both user and items contain n latent factor and passed into the network (Stochastic Gradient Descent), and their dot product is being compared with the actual user-item interaction matrix. In a nutshell, matrix factorization works by disintegrating the user-item interaction matrix into the product of two lower dimensionality rectangular matrices. Sometimes a bias term is also added in with the embeddings to incorporate any particular preference towards a specific item or user.
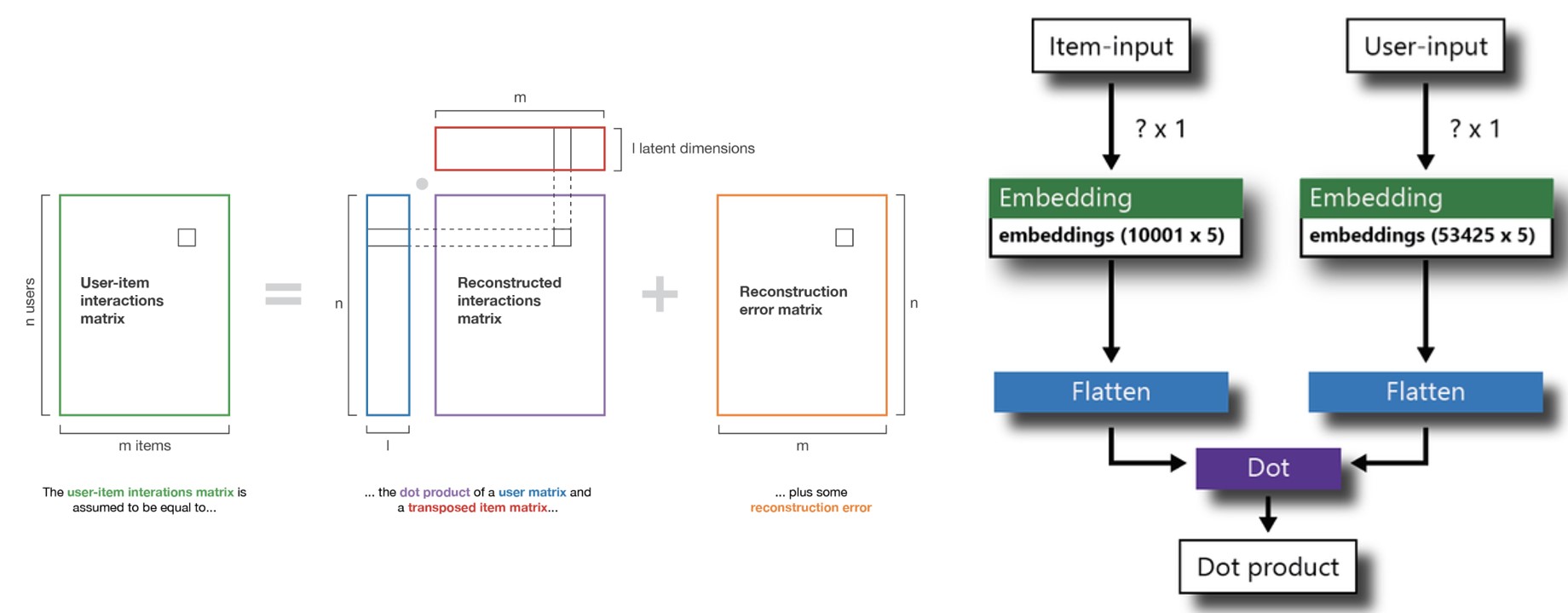
With the neural matrix factorization method, we were able to reduce RMSE to 0.83. Content-based recommendation system received a strong personalized score taking the textual features into consideration. This problem can be applied to the classification problem for future research using collective Filtering and substantial analysis could be done to deal with the cold-start problem.