

Sentiment Analysis on Amazon Cellphone Reviews with Effect of Negation
Sentiment analysis is one of the sub-domains of Natural Language Processing (NLP) that is of piqued interest in the research community. Negative sentences or using negations in sentences have a significant impact on sentiment polarity detection. In this study, we provide a novel end-to-end sentiment analysis approach to handle negations, along with the inclusion of negation identification and negation scope. Our approach outlines each step of the sentiment analysis process, including text pre-processing and vectorization of text, and introduces a customized negation marking algorithm for explicit negation detection. The paper also performs experiments on sentiment analysis with different supervised learning algorithms such as Naïve Bayes, Support Vector Machines, Artificial Neural Network (ANN), and Recurrent Neural Network (RNN) on sentiment analysis of Amazon reviews, specifically of cell phones.
In this project, we focus on tackling the following three research questions:
In order to validate our approach, we choose the Amazon reviews dataset obtained from Kaggle and which contains information on different cellphones such as brand, image URL, number of reviews, average rating, etc. The dataset also contains information on each review, such as review title, review body, and verified user. The dataset includes 82,000 reviews of 792 different cellphones produced by 10 major brands. The attributes which are expected not to play a significant role in determining the sentiment, such as URL, image, review URL, and name, were removed. Also, verified users were only considered in order to make the data more reliable, which left around 75,000 reviews for analysis and modeling.
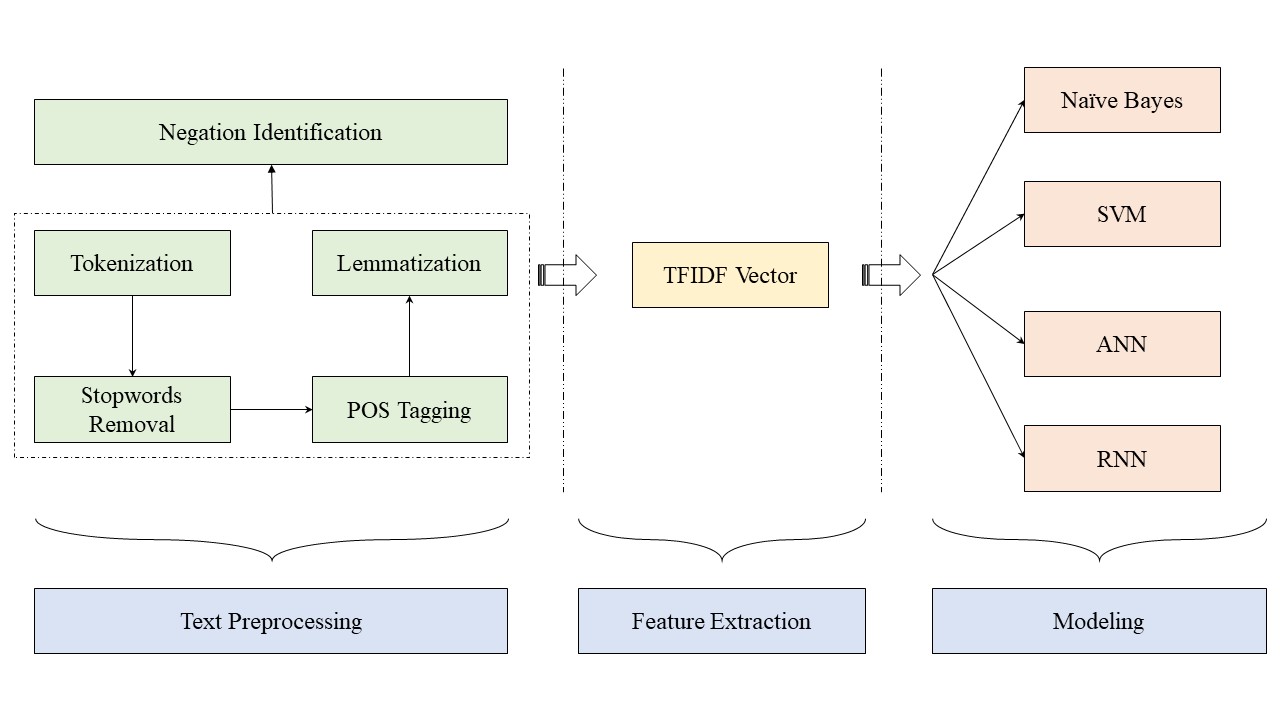
The above diagram provides an overview of our methodology used for this project. We start with basic text preprocessing followed by extracting textual features using TFIDF and finally apply various machine learning and deep learning classification models to our generated TFIDF. For analyzing the effect of negations, we tweak the text preprocessing process and apply our custom algorithm to the tokens.
By evaluating the effect of the negation algorithm on the sentiment analysis tasks, the RNN achieved the best accuracy of 95.67% when combined with our negation marking processing, exceeding its accuracy without any identification of negative sentences. Deep learning models (ANN, RNN) provided a significant improvement in performance over the traditional machine learning models. Further, our approach was applied to another dataset of Amazon reviews and demonstrated a significant improvement in the overall accuracy with the deep learning models, but, the traditional machine learning models’ performances decreased in comparison to the original dataset.